
In today’s fast-evolving e-commerce, especially after the advent of the highly competitive quick-commerce that promises the best product at your doorstep in minutes, personalization has become key to enhancing user experience and satisfaction. However, using LLMs for personalized recommendations has found its way into mainstream businesses such as entertainment and online learning, with companies spending millions and billions developing AI tools that promise spot-on recommendations to users.
Traditional recommendation algorithms have relied on collaborative filtering, content-based filtering, or hybrid recommendation systems, but they often struggle with data sparsity, cold-start problems, and a limited ability to capture nuanced user preferences and complex item interactions. With Large Language Models (LLMs) transforming the field, recommender systems are now leveraging advanced techniques such as Retrieval-Augmented Generation (RAG) to integrate external knowledge, reduce hallucinations, and improve recommendation accuracy by providing more contextually aware and dynamically updated suggestions.
This article will explore and provide an understanding of the architecture, advantages, challenges, and advanced techniques of RAG-powered LLM-based personalized product recommendation systems and their potential to revolutionize the recommendation system landscape.
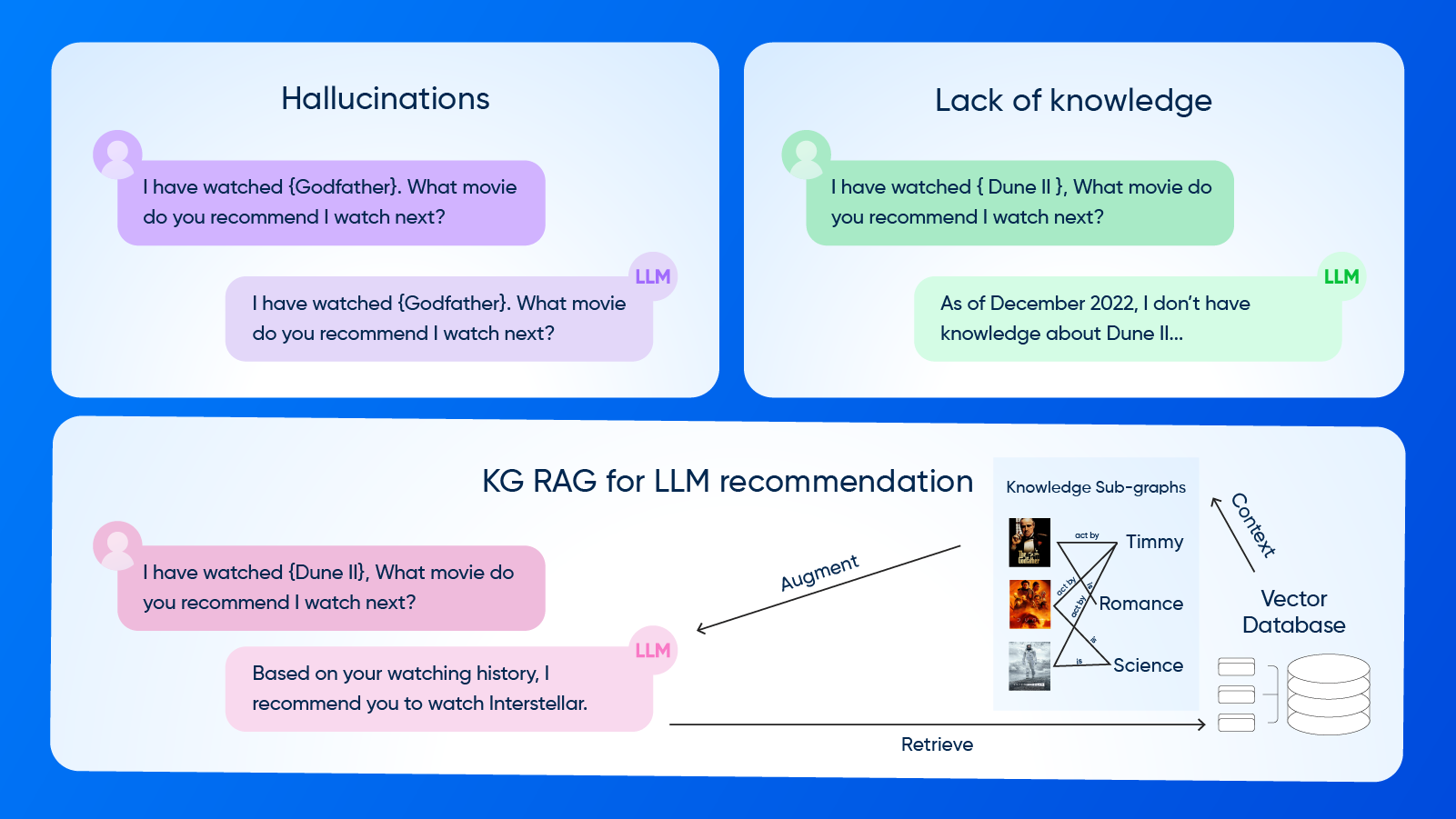
Understanding how LLMs with RAG act as a better Recommendation System
The widely used Large Language Models (LLMs), like OpenAI’s ChatGPT, Meta’s LLaMA, and Anthropic’s Claude, are trained on large datasets to generate coherent and contextually relevant text based on user prompts. Applying the same concept to the recommendation domain, these LLMs can analyze user profiles, past interactions, and item attributes to provide personalized recommendations. However, these LLMs come with one primary limitation: hallucinations. Since LLMs are trained on extensive datasets, they may generate inaccurate or non-existent recommendations because they cannot verify information or understand real-world context, especially when incorporating real-time product updates, trends, and customer reviews.
To address this issue, Retrieval-Augmented Generation (RAG) has been introduced as a mechanism to enhance LLMs with external knowledge retrieval capabilities, extracting pertinent information from databases or external sources such as:
- Product databases (e.g., product catalogs on e-commerce platforms)
- User-generated content (e.g., reviews, forums, blogs, and ratings provided by users)
- Knowledge graphs (e.g., Google’s Knowledge Graph, Wikidata)
- Real-time market trends and pricing updates
This allows the LLM to focus on the most relevant data instead of relying solely on pre-trained data before generating a response. This increases the model's efficiency and accuracy while overcoming data sparsity and hallucinations.
Architecture of RAG-Powered LLM-Based Recommendation System
A RAG-based personalized recommendation system consists of the following core components:
User Profile and Interaction Data Processing
- Data Collection and Preprocessing: The first step in building such a recommendation system is to aggregate the user data, including the browser history, purchase behavior, session interactions with history, and any explicit feedback. After this, the data collected is cleaned and normalized, eliminating noises and outliners for efficient processing.
- Feature Engineering: This includes extracting meaningful features from the collected data to create a comprehensive user representation.
- Transformer-based embeddings: Using transformers like BERT or TR to generate dense embeddings for users and products to learn contextual relevance and capture long-range dependencies.
Temporal Context Awareness: Implementing a time-sensitive model to provide relevant data by tracking seasonal trends and user activity fluctuations along with dynamic preferences.
Retrieval Mechanism through Vectorized Database
- Vector Embeddings Storage: Using a high-performance vector database like Pinecone or FAISS for storing the user and product embeddings generated by the transformers and faster retrieval and reliability.
- Semantic Search Algorithms: Implementing approximate nearest neighbor (ANN) search techniques such as HNSW, ScaNN, and Dense Passage Retrieval (DPR) to fetch the most relevant recommendations based on the users’ prompt.
- Personalized Retrieval Augmentation: Adjusting retrieval weightings dynamically based on user engagement signals to refine query relevance.
Multi-Modal Retrieval: To have a holistic understanding of user preferences through images and video by integrating a Vision Transformer or a CNN-based architecture. After training, the cosine similarity of any image and text embedding pair can be computed to determine how well they match.
Knowledge Graph Integration
- Graph Neural Networks (GNNs): Using an advanced GNN architecture like GraphSAGE, GAT, or Transformer-based GNNs to encode complex relationships between entities like products.
- Entity Resolution and Linking: Enhance product retrieval by linking user profiles with product details and metadata provided across multiple data sources.
- High-Order Relationship Extraction: Capturing deeper contextual relationships between the user expectation and retrieval (e.g., "users who purchased similar items also browsed complementary products") to generate insightful recommendations.
Explainable Recommendations: Generating structured and interpretable recommendations for the user based on knowledge graph reasoning.
LLM-Based Generation Module
- Fine-Tuned LLMs: Customizing available pre-trained models like GPT-4, LLaMA-3, and Mistral for recommendation-specific tasks given in the prompt for improving contextual understanding.
- Prompt Engineering and Few-Shot Learning: Construct some dynamic prompts that include user history and retrieved data to improve personalized responses.
- Soft Prompting Techniques: Using prefix-tuning and adapter layers to efficiently inject retrieved knowledge into LLM responses without full model retraining.
Multi-Turn Conversational Recommendations: Supporting interactive recommendation dialogues used for iterative refinement of the model based on user feedback.
Ranking and Optimization Module
- Hybrid Ranking Model: Integrating traditional recommendation models like collaborative filtering, content-based filtering, and graph-based ranking to get multi-faceted recommendations.
- Multi-Objective Optimization: Balancing factors such as relevance, diversity, novelty, and serendipity to improve recommendation quality to the user.
- Contextual Multi-Armed Bandits (CMAB): Implementing the reinforcement learning approaches (e.g., UCB, Thompson Sampling) to dynamically explore and exploit user preferences by selecting the action with the highest upper confidence bound.
Bias Mitigation Techniques: Identifying and correcting the biases in recommendation rankings for the system to ensure fair and equitable suggestions.
Evaluation Metrics and Reinforcement Learning Feedback Loop
- Multi-Modal Evaluation Metrics: Using evaluation metrics like Normalized Discounted Cumulative Gain (NDCG), Mean Average Precision (MAP), Recall@K, Mean Reciprocal Rank (MRR), and diversity scores to assess recommendation effectiveness.
- Reinforcement Learning (RL)-Based Training: Employing algorithms like deep Q-learning, PPO, and reward modeling to fine-tune recommendation logic based on user interactions.
- A/B Testing and Continuous Deployment: Implementing a few real-time evaluation pipelines to measure the impact of recommendation changes in production environments.
User Feedback Integration: Capturing explicit (e.g., ratings) and implicit (e.g., clicks, hover time) feedback by the users to continuously improve model performance.
Advantages of RAG-Enhanced LLM-Based Recommendation Systems
Enhanced Accuracy and Context Awareness
- Real-Time Knowledge Retrieval: based on the user prompt, it can dynamically fetch the latest product details along with trends and the latest reviews to provide an up-to-date recommendation.
- User Intent Understanding: it significantly improves contextual awareness by analyzing natural language queries and behavioral data of the user, reducing irrelevant recommendations.
Adaptive Personalization: it continuously updates the user profiles with the evolving preferences of users over time, refining recommendations.
Reduction in Hallucinations
- Grounded Response Generation: it ensures that recommendations provided by the system are fact-based by retrieving relevant supporting information from the data sources before generating responses for the user.
- Trustworthy Knowledge Sources: it integrates curated and high-confidence knowledge bases to mitigate misinformation risks.
Consistency Checks: They implement cross-referencing techniques to validate the retrieved information against multiple sources.
Adaptability to Dynamic Domains
- Domain-Specific Knowledge Integration: it enhances the recommendations by including industry-specific data (e.g., finance, healthcare, retail) in the recommendation system.
- Scalable Multi-Domain Adaptation: it allows the same RAG-powered model to serve diverse verticals with minimal reconfiguration just by changing the prompts and data sources.
Fine-Grained User Segmentation: It leverages clustering techniques to provide recommendations to users belonging to specific demographic or behavioral segments.
Improved Cold-Start Problem Handling
- Knowledge-Driven Recommendations: It uses external knowledge graphs and retrieval techniques to provide meaningful suggestions even for new users or products, eliminating the issue of the cold start of traditional recommendation algorithms.
- Zero-Shot Generalization: it enables the system to provide recommendations without requiring extensive historical interactions by leveraging pre-trained LLM capabilities.
Progressive User Modeling: it captures user intent early in the interaction process, which helps the system to adapt recommendations dynamically as more data becomes available.
Explainability and Transparency
- Rationale-Aware Recommendations: Provide a clear explanation (e.g., "This item is recommended because it shares similar features with your past purchases.") of the recommendation to increase the trust of the user.
- Visual Justification Models: it displays supporting evidence (e.g., product descriptions, customer reviews) alongside recommendations based on user preferences.
- Regulatory Compliance: it aligns with AI ethics guidelines to ensure fair and transparent recommendation outputs of the system.
Ready to transform your user experience with AI? Book a free consultation, and let's explore how our AI solutions can drive engagement, personalize learning, and boost your bottom line for your edtech business.

Gaurav has 19+ years of experience building and managing scalable web and mobile apps end-to-end, including product design, frontend/backend development, deployment, server management, uptime, performance, and reliability.
